决策树方法的主要思想是从树根开始,把任务按顺序分解为一个个选择,一步步进行到叶子节点,最终得到分类的结果。
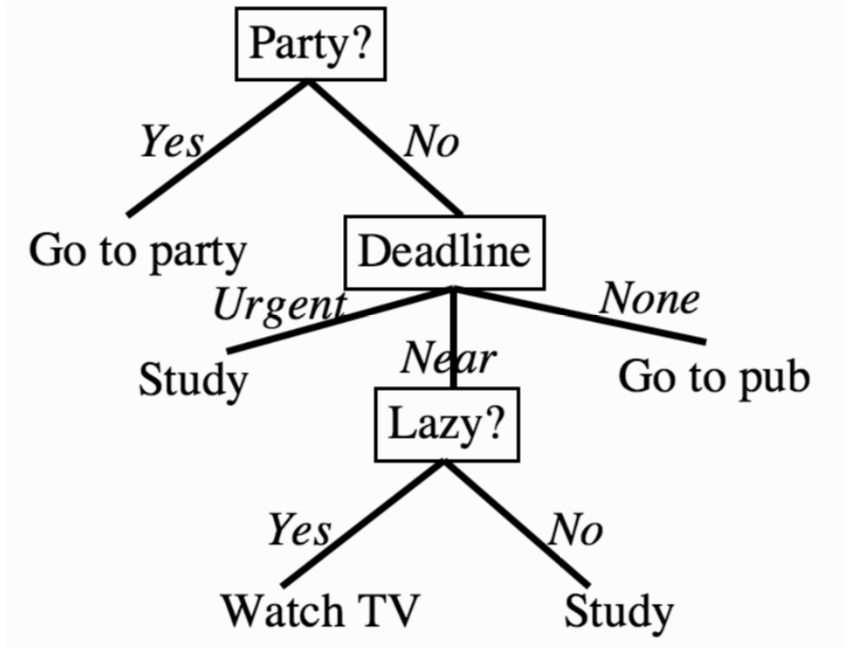
构建决策树
可与从根节点开始通过贪婪法构建树,每一步都选择富含信息量的特征,比如ID3算法,C4.5,CART等。
数学上完成这种任务的方法叫信息论。
信息论中的熵
信息熵(information entropy)可以度量描述特征集合的冗余量,概率集合Pi的熵H定义为:
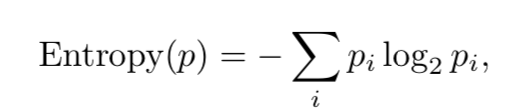
对数底数为2是因为二进制编码,同时定义0log0=0。
假设我们有一个正例和反例的结合,都是二值特征(只包含正值和负值),如果所有的样本为正,那么从样本的任一特征取值中得不到任何额外信息,因为不管取什么值样本都为正,这时特征熵为0。
而如果一个样本,正例反例各占一半,那么熵总量达到最大值,也最有用。
计算熵的函数:

正例的比例与熵值关系图(熵图):
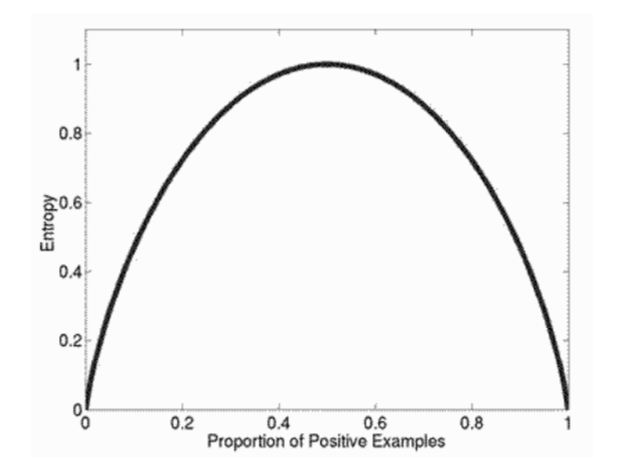
对决策树来说,最好的特征就是选择目前对分类能提供最大信息的那个,也就是有最大熵的特征。
ID3
通过熵,我们只要计算每个特征的熵并选择就好。ID3的核心思想:在决策树下一次分类是,对每个特征通过计算整个训练集的熵的减少来选择特征,这也叫信息增益(information gain)。
| 下列式子表述了信息增益,其中S是集合样本,F是所有可能样本之外的可能特征, | Sf | 是S中特征F的值为f的成员数目: |
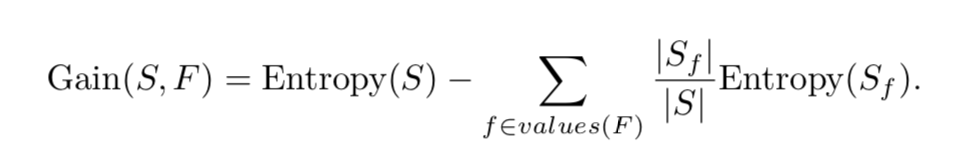
举例:
假设有一个数据集合(有标记)S={s1=true,s2=false,s3=false,s4=false},特征F的值为{f1,f2,f3},那么可以计算S的熵:
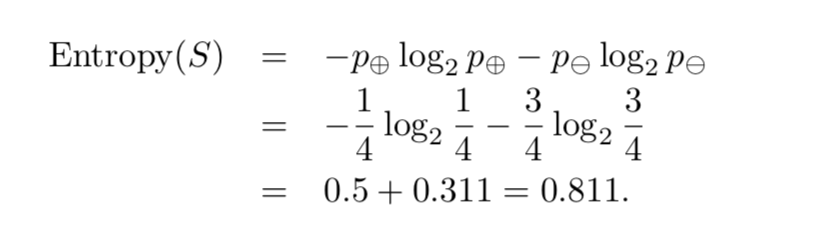
以此类推。
ID3算法:

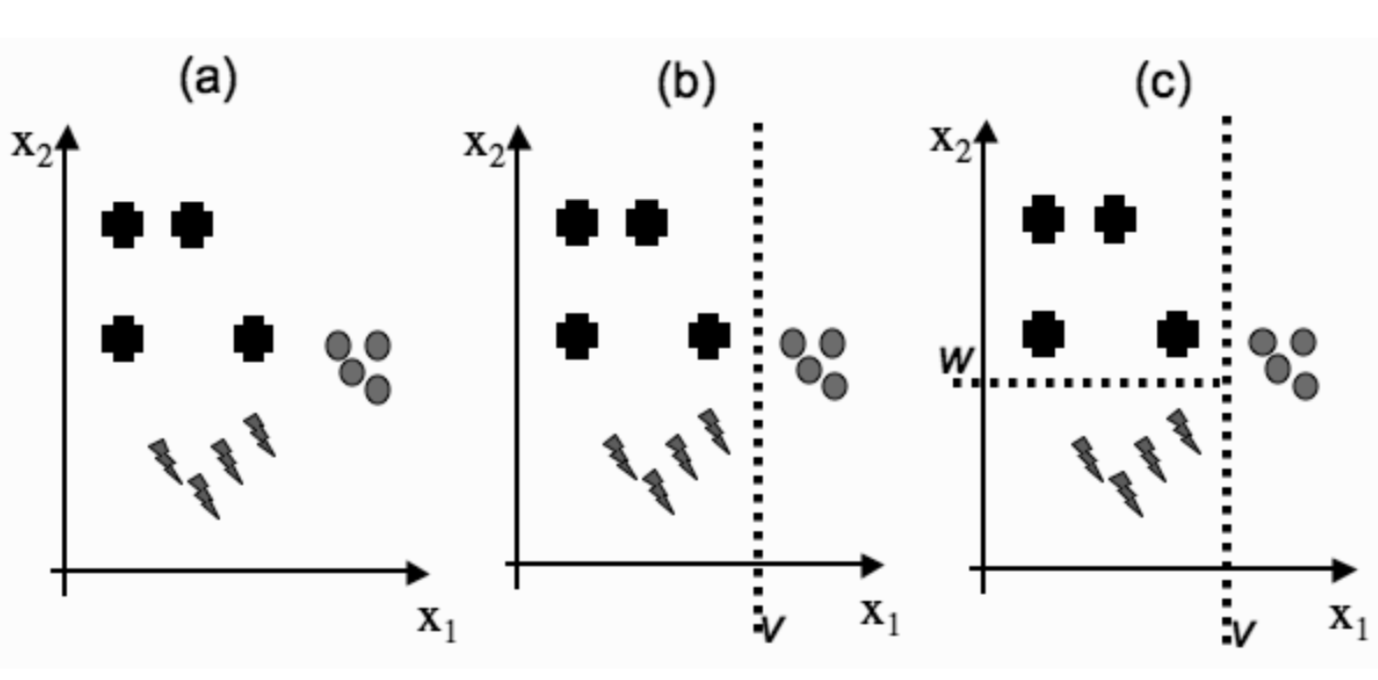
处理连续变量
可以对连续变量进行离散化,或者保持连续并修改算法。
对于连续变量,变量可以在任何一对数据点之间断开,这些算法生成的是单变量树,因为它们一次选择一个特征(维度)并根据该特征分割。
还有一些算法通过选择特征组合来生成多变量树。
计算复杂度
二叉树构造时间复杂度为O(NlogN),用于返回特定的时间复杂度为O(logN),其中N是节点的数量,但这是平衡二叉树的情况,而决策树通常不平衡。
假设树近似平衡,那么每个节点的成本包括搜索d个可能的特征,然后计算每个分裂的数据集的信息增益,which cost O(dnlogn),n是该节点上数据集的大小。
对于根节点,n=N,并且如果树平衡,则在树的每个阶段将n除以2。在树中的大约logN层级对此求和,得到计算成本O(dN^2logN)。
基尼不纯度
CART是另一种树算法,可以用于分类和回归。
不纯度表明决策树的目的是让每个叶节点代表同一类中的一组数据点,这样就不存在不匹配,这被称为纯度,如果叶子是纯的,那么其中所有训练数据只有一个类。
此情况下,如果我们计算属于类i的节点的数据点数称为N(i),那么除了i的一个值之外其他应该为0。
通过循环便利不同的特征并计算每个类属于多少个点,对于任何特征k,可以计算:
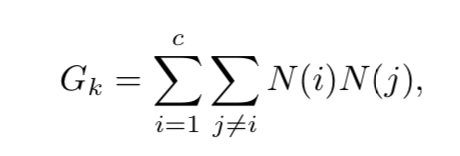
还可以增加错误分类的权重,引入矩阵,将i错误分类为j的成本:
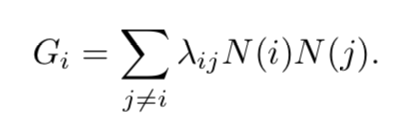
树回归
用平方和误差来实现,对于评估下一个要使用特征的选择,需要找到根据该特征拆分数据集的值,通常输出的只是位于该叶子中所有数据点的平均值。
Reference:
- Marsland S. Machine learning: an algorithmic perspective[M]. Chapman and Hall/CRC, 2014.