介绍
官方介绍:
IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。从3.0版本开始,IK发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。在2012版本中,IK实现了简单的分词歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。
搜索引擎对用户的理解通过各种自然语言处理技术完成,分词器就是其中一种通用而基本的方法。
本文的重点:
-
词典:词典树的构建与加载它的内存结构。
-
词法切分:词的匹配查找。
-
歧义判断:判断切分方式的合理性。
词典
IK分词器提供了3类词表:
-
主词表 main2012.dic
-
量词表 quantifier.dic
-
停用词 stopword.dic
具体的字典代码位于org.wltea.analyzer.dic.DictSegmen,这个类实现了分词器的核心结构:Tire Tree。
Tire Tree(字典树)是一种结构简单的树形结构,用于构建词典,通过前缀字符逐一比较的方式快速查找词,所以有时也称为前缀树。
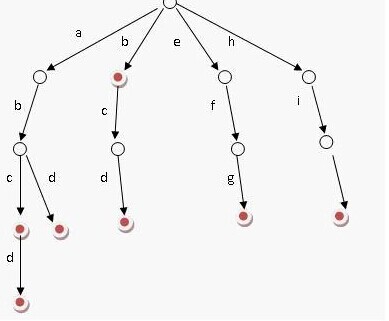
学过基础编译原理的就能理解这是啥了。中文字符也可以像这样处理,但是中文字符远远不止26个,会使这棵树扩散分散得非常厉害,很占用内存。(所以有个三叉字典树,但是IK没有用)
IK的实现方式比较简单:
class DictSegment implements Comparable<DictSegment>{
//公用字典表,存储汉字
private static final Map<Character , Character> charMap = new HashMap<Character , Character>(16 , 0.95f);
//数组大小上限
private static final int ARRAY_LENGTH_LIMIT = 3;
//Map存储结构
private Map<Character , DictSegment> childrenMap;
//数组方式存储结构
private DictSegment[] childrenArray;
//当前节点上存储的字符
private Character nodeChar;
//当前节点存储的Segment数目
//storeSize <=ARRAY_LENGTH_LIMIT ,使用数组存储, storeSize >ARRAY_LENGTH_LIMIT ,则使用Map存储
private int storeSize = 0;
//当前DictSegment状态 ,默认 0 , 1表示从根节点到当前节点的路径表示一个词
private int nodeState = 0;
……
根据阈值ARRAY_LENGTH_LIMIT,这里的存储有两种方式:如果子节点数不大于阈值,采用数组的方式childrenArray来存储;visa versa, 采用Map的方式childrenMap(由HashMap实现)来存储。
因为HashMap需要预先分配内存,所以可能存在浪费现象;但是如果全用数组存,后续采用二分查找时无法获得O(1)的时间复杂度。所以这里采用了两种方式,子节点少时用数组存,子节点多时则迁移至HashMap。
在构建过程中,会将每个词递归地一个个加入字典树:
/**
* 加载填充词典片段
* @param charArray
* @param begin
* @param length
* @param enabled
*/
private synchronized void fillSegment(char[] charArray , int begin , int length , int enabled){
……
//搜索当前节点的存储,查询对应keyChar的keyChar,如果没有则创建
DictSegment ds = lookforSegment(keyChar , enabled);
if(ds != null){
//处理keyChar对应的segment
if(length > 1){
//词元还没有完全加入词典树
ds.fillSegment(charArray, begin + 1, length - 1 , enabled);
}else if (length == 1){
//已经是词元的最后一个char,设置当前节点状态为enabled,
//enabled=1表明一个完整的词,enabled=0表示从词典中屏蔽当前词
ds.nodeState = enabled;
}
}
}
lookforSegment在子树的子节点中查找,如果少于ARRAY_LENGTH_LIMIT,则是数组存储,采用二分查找;反之则是HashMap,直接查找。
词语切分
IK分词器基本分为两种模式:smart模式和非smart模式。
例如关于:分词器分为两种模式
| smart模式下的分词结果:分词器 | 分为 | 两种 | 模式 |
| 非smart模式下的分词结果:分词器 | 分词 | 分为 | 两种 | 两 | 模式 |
非smart模式会将能分出来的词全部输出,smart模式会根据内在方法输出一个认为最合理的分词结果,这就涉及到了歧义判断。
看一下最基本的元素结构类:
public class Lexeme implements Comparable<Lexeme>{
……
//词元的起始位移
private int offset;
//词元的相对起始位置
private int begin;
//词元的长度
private int length;
//词元文本
private String lexemeText;
//词元类型
private int lexemeType;
……
这个Lexeme即是词元,起始位置阿位移阿长度啥的其实可以通过字面意思理解。要注意的是它是实现Comparable的,阅读比较算法可以发现起始位置靠前的优先,长度较长的优先。
这可以用来决定一个词在一条分词结果的词元链中的位置,可以用于得到上面例子中分词结果中的各个词的顺序。
词元链也很重要:
/**
* Lexeme链(路径)
*/
class LexemePath extends QuickSortSet implements Comparable<LexemePath>
一条LexmePath就是一种分词的结果,根据前后顺序组成链式结构。可以看到它扩展了QuickSortSet,所以它在加入词元时就在内部进行了排序,形成有序链,排序的实现还是Comparable,用于后面的歧义分析。
AnalyzeContext也是个重要的结构,存储了输入信息的文本、切分出来的lemexePah、分词结果等一些相关的上下文信息。
IK中默认用到三个子分词器,分别是LetterSegmenter(字母分词器),CN_QuantifierSegment(量词分词器),CJKSegmenter(中日韩分词器)。分词会先后经过这三个分词器,我们重点根据CJKSegmenter分析。
CJKSegmenter核心是一个analyze方法:
public void analyze(AnalyzeContext context) {
……
//优先处理tmpHits中的hit
if(!this.tmpHits.isEmpty()){
//处理词段队列
Hit[] tmpArray = this.tmpHits.toArray(new Hit[this.tmpHits.size()]);
for(Hit hit : tmpArray){
hit = Dictionary.getSingleton().matchWithHit(context.getSegmentBuff(), context.getCursor() , hit);
if(hit.isMatch()){
//输出当前的词
Lexeme newLexeme = new Lexeme(context.getBufferOffset() , hit.getBegin() , context.getCursor() - hit.getBegin() + 1 , Lexeme.TYPE_CNWORD);
context.addLexeme(newLexeme);
if(!hit.isPrefix()){//不是词前缀,hit不需要继续匹配,移除
this.tmpHits.remove(hit);
}
}else if(hit.isUnmatch()){
//hit不是词,移除
this.tmpHits.remove(hit);
}
}
}
//*********************************
//再对当前指针位置的字符进行单字匹配
Hit singleCharHit = Dictionary.getSingleton().matchInMainDict(context.getSegmentBuff(), context.getCursor(), 1);
if(singleCharHit.isMatch()){//首字成词
//输出当前的词
Lexeme newLexeme = new Lexeme(context.getBufferOffset() , context.getCursor() , 1 , Lexeme.TYPE_CNWORD);
context.addLexeme(newLexeme);
//同时也是词前缀
if(singleCharHit.isPrefix()){
//前缀匹配则放入hit列表
this.tmpHits.add(singleCharHit);
}
}else if(singleCharHit.isPrefix()){//首字为词前缀
//前缀匹配则放入hit列表
this.tmpHits.add(singleCharHit);
}
……
}
下半截代码的matchInMainDict方法就是用于匹配主题表内的词的方法。这里的主词表已经加载至一个字典树之内,所以整个过程也就是一个从树根层层往下走的一个层层递归的方式,但这里只处理单字,不会去递归。
匹配的结果一共三种UNMATCH(未匹配),MATCH(匹配), PREFIX(前缀匹配)。
Match指完全匹配已经到达叶子节点,而PREFIX是指当前对上所经过的匹配路径存在,但未到达到叶子节点。此外一个词也可以既是MATCH也可以是PREFIX。前缀匹配的都被存入了tempHit中去。而完整匹配的都存入context中保存。
继续看上半截代码,前缀匹配的词不应该就直接结束,因为有可能还能往后继续匹配更长的词,所以上半截代码所做的就是对这些词继续匹配。matchWithHit,就是在当前的hit的结果下继续做匹配。如果得到MATCH的结果,便可以在context中加入新的词元。
通过这样不段匹配,循环补充的方式,我们就可以得到所有的词,至少能够满足非smart模式下的需求。
##歧义判断
IKArbitrator(歧义分析裁决器)是处理歧义的主要类。
上面不是说了,LexemePath是实现compareble接口的。
public int compareTo(LexemePath o) {
//比较有效文本长度
if(this.payloadLength > o.payloadLength){
return -1;
}else if(this.payloadLength < o.payloadLength){
return 1;
}else{
//比较词元个数,越少越好
if(this.size() < o.size()){
return -1;
}else if (this.size() > o.size()){
return 1;
}else{
//路径跨度越大越好
if(this.getPathLength() > o.getPathLength()){
return -1;
}else if(this.getPathLength() < o.getPathLength()){
return 1;
}else {
//根据统计学结论,逆向切分概率高于正向切分,因此位置越靠后的优先
if(this.pathEnd > o.pathEnd){
return -1;
}else if(pathEnd < o.pathEnd){
return 1;
}else{
//词长越平均越好
if(this.getXWeight() > o.getXWeight()){
return -1;
}else if(this.getXWeight() < o.getXWeight()){
return 1;
}else {
//词元位置权重比较
if(this.getPWeight() > o.getPWeight()){
return -1;
}else if(this.getPWeight() < o.getPWeight()){
return 1;
}
}
}
}
}
}
return 0;
}
这个就是IKAnalyzer分词消歧的核心,按照如下方式消歧:
-
比较有效文本长度
-
比较词元个数,越少越好
-
路径跨度越大越好
-
根据统计学结论,逆向切分概率高于正向切分,因此位置越靠后的优先
-
词长越平均越好
……
这些都是人为定的规则,按照统计方式进行消歧。
IKArbitrator还有一个judge方法,对不同路径进行比较。
private LexemePath judge(QuickSortSet.Cell lexemeCell , int fullTextLength){
//候选路径集合
TreeSet<LexemePath> pathOptions = new TreeSet<LexemePath>();
//候选结果路径
LexemePath option = new LexemePath();
//对crossPath进行一次遍历,同时返回本次遍历中有冲突的Lexeme栈
Stack<QuickSortSet.Cell> lexemeStack = this.forwardPath(lexemeCell , option);
//当前词元链并非最理想的,加入候选路径集合
pathOptions.add(option.copy());
//存在歧义词,处理
QuickSortSet.Cell c = null;
while(!lexemeStack.isEmpty()){
c = lexemeStack.pop();
//回滚词元链
this.backPath(c.getLexeme() , option);
//从歧义词位置开始,递归,生成可选方案
this.forwardPath(c , option);
pathOptions.add(option.copy());
}
//返回集合中的最优方案
return pathOptions.first();
}
这个就是从第一个词元开始,遍历各种路径,然后加入一个TreeSet中,实现排序后取第一个。
TreeSet的javaDoc的解释如下:
A NavigableSet implementation based on a TreeMap. The elements are ordered using their natural ordering, or by a Comparator provided at set creation time, depending on which constructor is used.
This implementation provides guaranteed log(n) time cost for the basic operations (add, remove and contains).
Note that the ordering maintained by a set (whether or not an explicit comparator is provided) must be consistent with equals if it is to correctly implement the Set interface. (See Comparable or Comparator for a precise definition of consistent with equals.) This is so because the Set interface is defined in terms of the equals operation, but a TreeSet instance performs all element comparisons using its compareTo (or compare) method, so two elements that are deemed equal by this method are, from the standpoint of the set, equal. The behavior of a set is well-defined even if its ordering is inconsistent with equals; it just fails to obey the general contract of the Set interface.
就是用上面实现的compareTo,这一步实现了消歧。
IKAnalyzer是在细粒度切分后的结果中进行消歧,首先是扫描未经过歧义消除的词源,遇到有歧义的词就放到LexemePath数据结构中,当遇到没有歧义的词后就出来LexemePath这个数据结构,对其进行消歧,消歧后的LexemePath放到了 Map<Integer , LexemePath>数据结构中,最后对这个数据结构进行合并把结果放到LinkedList
void process(AnalyzeContext context , boolean useSmart){
QuickSortSet orgLexemes = context.getOrgLexemes();
Lexeme orgLexeme = orgLexemes.pollFirst();
LexemePath crossPath = new LexemePath();
while(orgLexeme != null){
if(!crossPath.addCrossLexeme(orgLexeme)){
//找到与crossPath不相交的下一个crossPath
if(crossPath.size() == 1 || !useSmart){
//crossPath没有歧义 或者 不做歧义处理
//直接输出当前crossPath
context.addLexemePath(crossPath);
}else{
//对当前的crossPath进行歧义处理
QuickSortSet.Cell headCell = crossPath.getHead();
LexemePath judgeResult = this.judge(headCell, crossPath.getPathLength());
//输出歧义处理结果judgeResult
context.addLexemePath(judgeResult);
}
//把orgLexeme加入新的crossPath中
crossPath = new LexemePath();
crossPath.addCrossLexeme(orgLexeme);
}
orgLexeme = orgLexemes.pollFirst();
}
//处理最后的path
if(crossPath.size() == 1 || !useSmart){
//crossPath没有歧义 或者 不做歧义处理
//直接输出当前crossPath
context.addLexemePath(crossPath);
}else{
//对当前的crossPath进行歧义处理
QuickSortSet.Cell headCell = crossPath.getHead();
LexemePath judgeResult = this.judge(headCell, crossPath.getPathLength());
//输出歧义处理结果judgeResult
context.addLexemePath(judgeResult);
}
}